
La mort dans l’internet
Introduction
Né il y a moins d’un demi-siècle, l’internet a déjà transformé nos modes de vie. C’est là que nous travaillons, discutons, achetons, vendons, protestons, nous confions et créons. Documents officiels, messages privés, pensées fugitives, œuvres inachevées – tout cela vit ici. Ce que nous considérons comme une routine quotidienne est en réalité l’histoire que nous écrivons jour après jour.
On croit souvent qu’Internet est permanent, une immense archive où tout resterait accessible. Mais c’est un mythe. En vérité, l’internet oublie. Les espaces numériques sont fragiles, les sites disparaissent, les forums s’effondrent, les communautés se dissolvent. Parfois lentement – liens brisés, images manquantes – fermetures, purges, effacements volontaires. Derrière cela, des décisions politiques, choix économiques ou tendances culturelles déterminent ce qui survit ou s’efface. De nouveaux mots apparaissent, les anciens disparaissent, les plateformes naissent et meurent. Et parfois, ce qui disparaît ne se fait pas par accident, mais par intention.
L’internet dont ma génération a hérité n’est pas le même que celui que les générations précédentes ont connu. Et celui que nous transmettrons ne sera pas le même non plus. Dans ce texte, nous abandonnons la nature mortelle d’un média contemporain. L’ascension et la chute des sites et forums emblématiques. L’effacement volontaire des espaces numériques. Les efforts des utilisateurs pour préserver. Que signifie perdre une partie de l’internet ? Que laisserons-nous aux générations futures ? Et qui décide de ce qui mérite d’être conservé ?
Début d’Internet
Les origines d’Internet remontent aux États-Unis des années 1950. Dans le contexte tendu de la guerre froide, les États-Unis ont cherché à développer un système de communication capable de survivre à une attaque nucléaire. À cette époque, les ordinateurs étaient de grandes machines coûteuses, utilisées exclusivement par des scientifiques militaires et des chercheurs universitaires. Ils étaient puissants mais peu nombreux.
Pour résoudre ce problème, les chercheurs ont commencé à utiliser le « time-sharing ». Cela signifiait que plusieurs utilisateurs pouvaient accéder simultanément à un ordinateur central via une série de terminaux, bien que chacun ne dispose que d’une fraction de la puissance réelle de la machine. La difficulté d’utilisation de ces systèmes a poussé divers scientifiques, ingénieurs et organisations à explorer la possibilité d’un réseau informatique à grande échelle.
Personne n’a inventé Internet à lui seul. Lorsque les technologies de réseau ont été développées, plusieurs chercheurs ont rassemblé leurs travaux pour créer l’ARPANET*. Plus tard, d’autres innovations – comme les protocoles de communication et le World Wide Web – ont ouvert la voie à l’Internet tel que nous le connaissons aujourd’hui.

L’invention du World Wide Web
En 1989, le chercheur britannique Tim Berners-Lee, travaillant au CERN*, a proposé un système permettant aux chercheurs de partager des informations entre différents ordinateurs. Son idée combinait l’hypertexte et les réseaux, permettant de lier des documents et d’y accéder à distance. En 1990, Berners-Lee avait développé : HTML*, HTTP* et URL*. Le premier site web, hébergé sur son ordinateur NeXT, est mis en ligne en 1991. Il expliquait ce qu’était le Web et comment l’utiliser. En 1993, le CERN a rendu le logiciel accessible au domaine public.

À mesure que le Web s’est répandu à l’échelle mondiale, il a donné naissance à des sites, des forums et des plateformes créatives – des espaces où des communautés se formaient, où les idées circulaient, et où la culture numérique prospérait. Mais le Web initial reposait sur des bases fragiles. Les mises à jour techniques, les exigences en matière de sécurité et les restructurations ont progressivement changé son architecture.
Ascension et chute des sites et forums les plus emblématiques
Les forums, dans leur sens moderne, sont des espaces de discussion en ligne ou des centres communautaires. Ce sont des lieux où des personnes partageant des intérêts communs – comme le jeu vidéo, la programmation, la parentalité ou la politique — échangent des conseils, résolvent des problèmes ou discutent simplement.
Avant la naissance du World Wide Web, les utilisateurs se connectaient via Usenet, un réseau de discussion décentralisé lancé en 1980. Il permettait aux gens de publier des messages dans des groupes de discussion thématiques, formant ainsi l’une des premières communautés en ligne. À la même époque, les Bulletin Board Systems (BBS) apparaissent, gérés par des particuliers qui hébergeaient des serveurs locaux accessibles par ligne téléphonique.
En 1993, la mise à disposition du Web dans le domaine public permet à toute personne ayant quelques connaissances en code de créer son propre site. Les premiers à adopter cette technologie sont des institutions académiques comme le SLAC* et le NCSA*, qui hébergent des pages de recherche et des annuaires. Mais très vite, les sites personnels et les forums commencent à dominer Internet.
GeoCities suit en 1994, proposant un hébergement gratuit et organisant les sites en « quartiers » thématiques. Cela permet à des millions d’utilisateurs de créer des pages personnelles, des sites de fans et des journaux numériques. Ce ne sont pas des plateformes corporatives – elles sont construites par des individus, souvent sans formation technique, animés par la curiosité et la créativité.
À mesure que le Web mûrit, des forums comme phpBB et vBulletin donnent naissance à des communautés spécialisées : clans de joueurs, fandoms* d’anime, forums d’assistance technique, et espaces de discussion régionaux. Certains, comme Newgrounds*, combinent forums et médias en Flash, devenant des centres d’animation et d’art interactif.
Les systèmes BBS
Ces sites et forums ont pour la plupart disparu ou été perdus pour diverses raisons. Par exemple, les systèmes BBS commencent à disparaître dans les années 1990 avec la montée en puissance du Web, et bon nombre des programmes et communautés qui leur étaient associés s’effacent également. La transition vers le Web n’a pas été douce. Dans les années 1990, la plupart des sysops (administrateurs de BBS) ne migrent pas leurs forums vers le Web. Il n’existait pas de méthode simple pour convertir les journaux de messages BBS en HTML ou en logiciels de forum.

Friendster
Friendster, lancé en 2002, est rapidement devenu un pionnier des réseaux sociaux en ligne. Avant que Facebook ou Instagram ne dominent le paysage, Friendster était l’endroit où des millions de personnes se connectaient, partageaient des photos et construisaient des amitiés numériques.
Mais à mesure que sa base d’utilisateurs grandissait, les problèmes techniques se multipliaient. Le site souffrait de lenteurs, de pannes fréquentes et de difficultés de mise à l’échelle. Les utilisateurs ont commencé à partir vers des plateformes plus rapides et plus fiables comme MySpace, puis Facebook. Pour tenter de survivre, Friendster a essayé de se réinventer en 2011 en tant que site de jeux sociaux — délaissant les profils et les connexions au profit de jeux en ligne et de biens virtuels. Ce virage n’a pas fonctionné. La plateforme de jeux n’a pas attiré suffisamment d’utilisateurs, et en 2015, Friendster a fermé définitivement. Ses archives, messages et profils n’ont pas été conservés.
GeoCities
GeoCities était autrefois un service d’hébergement web très populaire, fondé en 1994 et racheté par Yahoo* en 1999. Marqué par son généreux quota de 15 mégaoctets et sa gratuité
(avec publicités intégrées), il fut à un moment donné le troisième site le plus consulté du World Wide Web.
Parce que le site était gratuit et principalement destiné aux nouveaux utilisateurs d’Internet, la qualité des pages hébergées sur GeoCities est vite devenue une blague récurrente – mise en page amateur, gifs animés, sites très personnels : tout cela dominait les pages typiques de GeoCities, souvent abandonnées par leurs créateurs peu après avoir trouvé de meilleures façons de raconter leurs histoires ou de présenter leurs données.

En avril 2009, Yahoo annonce la fermeture de GeoCities « plus tard dans l’année ». En juillet 2009, la date officielleest fixée au 26 octobre 2009, et Yahoo propose plusieurs offres d’hébergement payant pour transférer les données versces nouveaux services.
GeoCities est fermé par Yahoo en raison de sa perte de pertinence, de son manque de rentabilité et d’un changement stratégique dans le modèle économique de l’entreprise. Bien qu’il ait été l’un des sites les plus visités à la fin des années 1990, GeoCities n’a jamais généré de revenus significatifs. Après son acquisition en 1999, Yahoo s’oriente progressivement vers des services d’hébergement payants et des plateformes de contenu plus centralisées. Les utilisateurs sont encouragés à migrer vers Yahoo Web Hosting.
GeoCities a représenté, pour des millions de personnes, leur première expérience avec un site web accessible au monde entier, en couleur, à faible coût - et toutes les possibilités que cela impliquait. Ne pas avoir au moins la possibilité de consulter ces anciens sites revient à perdre une partie de l’histoire du Web, celle des gens qui l’ont découvert.
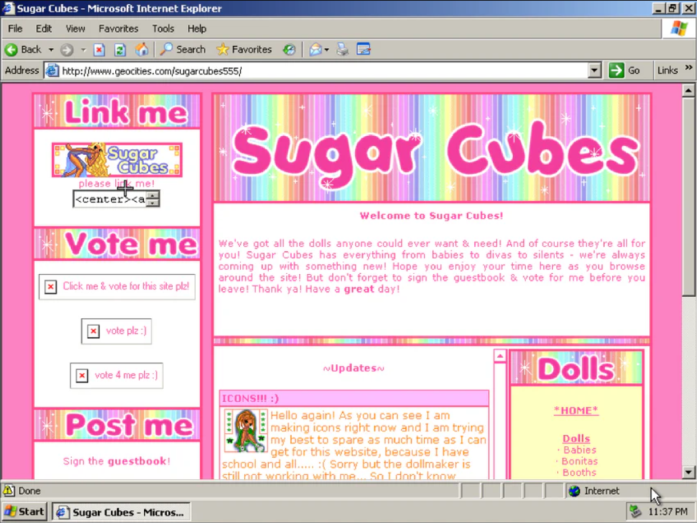
À mon avis, GeoCities est une pièce très intéressante de l’histoire d’Internet, et le fait que je n’en aurais même pas entendu parler sans mes recherches me fait presque mal physiquement. Parcourir ces vieilles pages datant d’il y a des années révèle une richesse d’humanité et de créativité. Certaines pages sont faites de manière assez professionnelle, d’autres sont un peu gênantes mais aussi tellement charmantes à leur façon. Des gifs brillants et animés, parfois un peu absurdes, des photos prises avec une caméra domestique, et une personnalisation sans limites. C’est exactement ce que j’imaginais la première fois que j’ai commencé à apprendre le code, et c’est cent pour cent ce qui rend l’ancien Internet si précieux à mes yeux.
Avec les réseaux sociaux modernes, dans le meilleur des cas, vous pouvez changer votre nom d’utilisateur, votre photo de profil et votre bannière. Mais ils manquent de personnalisation, privilégiant un style unique et un format strict des pages. Bien pour la cohérence de marque, mauvais pour l’expression personnelle.
Le « S » dans HTTPS
HTTPS signifie HyperText Transfer Protocol Secure. Il s’agit de la version sécurisée du protocole HTTP, utilisé pour charger les pages web. La différence essentielle est que HTTPS chiffre les données échangées entre le navigateur de l’utilisateur et le site web, les protégeant ainsi contre toute interception ou altération. Cela est devenu de plus en plus important à mesure que l’internet s’est étendu aux transactions sensibles, aux données personnelles et aux comptes utilisateurs.
À partir de 2015 environ, les principaux navigateurs comme Chrome et Firefox ont commencé à encourager, voire à exiger l’usage de HTTPS. Les sites utilisant le HTTP simple étaient marqués comme « Non sécurisé », et certains navigateurs ont même commencé à les bloquer entièrement. Ce changement a été motivé par le besoin accru de confidentialité et de sécurité, en réponse aux inquiétudes croissantes concernant la surveillance, le vol de données et les attaques malveillantes.
Si la transition vers HTTPS a renforcé la sécurité sur Internet, elle a aussi contribué à la disparition de nombreux sites anciens. Ces espaces, riches en mémoire culturelle et en histoire communautaire, étaient souvent construits sur des plateformes obsolètes ne prenant pas en charge les protocoles sécurisés. Faute de mises à jour techniques ou de ressources pour répondre aux nouvelles normes, ils ont été signalés comme non sûrs, retirés des index de recherche ou fermés — accélérant ainsi la perte du web amateur et décentralisé.
Quelques exemples de ce que nous avons perdu :
Tripod et Angelfire — des plateformes d’hébergement gratuites pour blogs personnels et communautés spécialisées. De nombreux sites ont été abandonnés et jamais mis à jour vers HTTPS. Lycos a fini par supprimer une grande partie du contenu en raison de l’inactivité et de l’obsolescence technique.
Archives universitaires et projets de recherche — des sites académiques anciens, créés dans les années 1990 et au début des années 2000, étaient souvent hébergés sur des serveurs uniquement en HTTP. Lors de la migration vers de nouvelles plateformes, le contenu hérité n’a pas toujours été conservé. Certains projets en humanités numériques et archives étudiantes ont été perdus dans la transition.
Sites artistiques et médiatiques basés sur Flash — les sites combinant HTTP et contenu Flash sont devenus doublement obsolètes. Cela inclut des portfolios de net.art, des projets de narration interactive et des vitrines de design expérimental. La fin de Flash en 2020, combinée à l’application du HTTPS, les a rendus inaccessibles, même via les archives.
Fin de Flash
Adobe Flash a été officiellement abandonné le 31 décembre 2020, marquant la fin de l’une des plateformes logicielles les plus influentes de l’histoire d’Internet.
Initialement développé par Macromedia au milieu des années 1990, puis racheté par Adobe, Flash a permis aux créateurs de concevoir des animations, des jeux, des sites interactifs
et des expériences multimédias qui ont façonné le Web des débuts.


La fermeture de Flash résulte de plusieurs facteurs. On peut dire que la fin de Flash Player a commencé en 2007, lorsque Apple a lancé le premier iPhone, qui ne prenait pas en charge Flash. Cela a obligé YouTube et d’autres sites populaires à abandonner Flash pour rester compatibles avec les appareils Apple. En 2010, Apple a supprimé tout support de Flash sur ses téléphones, ordinateurs et tablettes. Les principaux navigateurs ont suivi, bloquant complètement le contenu Flash dès janvier 2021.
Flash souffrait également de nombreuses failles de sécurité, en faisant une cible fréquente pour les logiciels malveillants et les attaques. Il consommait beaucoup de ressources système et n’était pas adapté aux appareils mobiles. L’émergence de standards ouverts comme HTML5*, WebGL* et WebAssembly* a offert des alternatives plus sûres, plus rapides et plus flexibles.
Cela a entraîné la disparition de milliers de sites, jeux et œuvres créés avec Flash. Beaucoup n’ont jamais été correctement archivés et sont devenus inaccessibles du jour au lendemain. Cela inclut des projets de net.art, des expérimentations narratives interactives et des portfolios personnels entièrement conçus en Flash. Certains projets, comme Flashpoint de BlueMaxima, ont tenté de préserver ces créations via l’émulation et des archives hors ligne, mais une grande partie du contexte original et des communautés associées a disparu.
Internet murder
J’utilise le terme « internet murder » pour désigner les situations où des sites, forums ou autres espaces en ligne sont supprimés, et où la majorité – voire la totalité – de leurs données sont perdues, non pas à cause du vieillissement, de l’obsolescence ou de circonstances accidentelles, mais volontairement. Par des gouvernements, des groupes de hackers ou d’autres entités, dans un but de censure, de sécurité, de propagande politique, de lutte contre le terrorisme ou autre.
Parmi les exemples, on peut citer les fermetures ordonnées par les gouvernements, comme Le Grand Firewall de Chine – un système complexe de censure, de surveillance et de contrôle d’accès. Des milliers de sites, dont Google, Facebook et Wikipédia, y ont été bloqués. De nombreux forums et blogs locaux ont été fermés ou nettoyés de force, effaçant les voix dissidentes et les archives historiques.
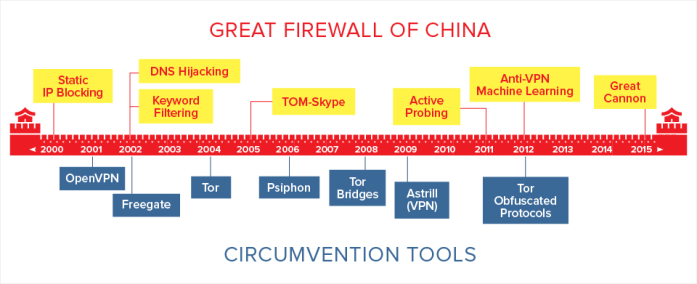
Exemple : cyberattaques, hacktivisme ou suppressions liées à la sécurité, comme lors des campagnes contre la propagande de l’État islamique. Gouvernements et entreprises ont fermé des milliers de sites et forums extrémistes. Nécessaires pour la sécurité, ces suppressions ont aussi effacé des archives entières, compliquant l’étude de la radicalisation.
Ou encore le coup d’État au Myanmar en 2021. Les autorités militaires ont coupé l’accès à Internet et bloqué les réseaux sociaux pour empêcher la coordination des manifestations. De nombreuses pages militantes et sites d’information locaux ont été supprimés ou contraints à l’arrêt, effaçant des traces de violences et de résistance.

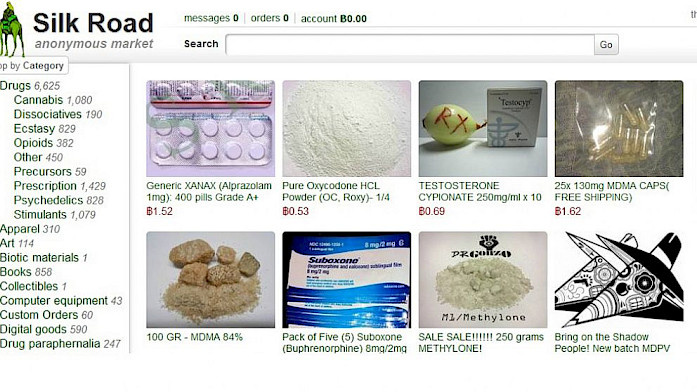
La fermeture de Silk Road en 2013 en est un autre exemple. Le FBI a démantelé ce marché du darknet et saisi ses serveurs. Bien que le site ait été illégal, sa suppression a aussi effacé des forums, des historiques d’utilisateurs et des données économiques devenues partie intégrante du folklore numérique.
Lavabit, 2013. Ce service de messagerie sécurisé utilisé par Edward Snowden a été fermé par son fondateur après que le gouvernement américain ait exigé l’accès aux données des utilisateurs. Plutôt que de céder, il a choisi de fermer le service et de supprimer tous les comptes.

Ces exemples peuvent sembler positifs ou négatifs selon les opinions. Mais ils créent un précédent : tout peut être effacé dès qu’on invoque « pour votre sécurité », sans devoir préserver l’histoire numérique des usagers et de l’humanité en ligne. Fermer des sites terroristes paraît juste, bien sûr. Mais que se passe‑t‑il si un gouvernement ou acteur redéfinit « terroriste », « criminel » ou « sécurité » ? Jusqu’où ira leur croisade contre
les contenus jugés nuisibles ? Et que laisserons‑nous aux générations futures ? Qui décide de ce qu’elles pourront voir ?
L’archivage de l’internet
Commençons par une question simple : qu’est‑ce que l’archivage
du Web ? C’est le processus de collecte, de conservation et de mise
à disposition de contenus issus du World Wide Web. Son objectif est de garantir que l’information numérique soit conservée dans un format archivistique, accessible au public et aux chercheurs.
Dix ans après sa création, le Web était déjà devenu un outil de communication largement utilisé. Individus et institutions produisaient d’énormes volumes de contenus purement numériques, sans équivalent imprimé. Dès 1997, Brewster Kahle
a souligné l’importance de préserver le Web dans un article publié dans une revue scientifique populaire (Kahle, 1997).

Photographie des serveurs de l’Internet Archive, San Francisco
Parmi les premières initiatives majeures figure l’Internet Archive, une organisation à but non lucratif fondée en 1996 par Brewster Kahle lui‑même. Basée à San Francisco, elle est devenue l’un des plus grands projets de préservation numérique au monde, avec plus de 866 milliards de pages web, 44 millions de livres et plus de 10 millions de documents audiovisuels. Sa mission est de fournir un accès universel à la connaissance et de défendre un internet libre et ouvert. Son outil le plus connu est la Wayback Machine, lancée en 2001, qui permet de consulter des versions archivées de sites web, parfois capturées plusieurs fois par jour.
D’autres pays ont lancé des projets similaires à la même époque : la Bibliothèque nationale du Canada, Pandora en Australie, Kulturarw3 en Suède. Aux États‑Unis, la Library of Congress archive les sites gouvernementaux et les sources d’actualité, et jusqu’en 2017, elle conservait l’intégralité des tweets publiés. Au Royaume‑Uni, le UK Web Archive collecte chaque année
les domaines .uk pour saisir des instantanés du Web.
En France, la Bibliothèque nationale de France (BnF) a commencé des collectes expérimentales en 1999, avec une première moisson d’envergure lors des élections présidentielles de 2002. En 2006, le Parlement français a intégré l’archivage du Web
dans le cadre du dépôt légal, reconnaissant les communications numériques comme patrimoine national. La BnF est ainsi chargée d’archiver le Web français, aux côtés de l’INA pour les médias audiovisuels et du CNC pour le cinéma. Depuis 2010, elle gère sa propre infrastructure technique et garantit la conservation à long terme de ses collections numériques, qui atteignaient environ 1 200 téraoctets et 35 milliards de fichiers fin 2019.
La collaboration internationale a également joué un rôle clé
dans l’élaboration des standards d’archivage. De 2001 à 2010, l’International Web Archiving Workshop (IWAW) a permis de partager des pratiques et des idées. En 2003, le International Internet Preservation Consortium (IIPC) a été créé pour promouvoir la coopération et développer des outils Open Source.

 Logo de l’International Web Association, International Web Association
Logo de l’International Web Association, International Web Association Capture d’écran du site de l’International Internet Preservation Consortium, IIPC, 2003
Mais l’archivage du Web est confronté à de nombreux problèmes :
Des vulnérabilités juridiques et des conflits de droits d’auteur – l’une des menaces les plus pressantes. Par exemple, l’Internet Archive a fait face à plusieurs procès qui mettent en péril sa mission et sa stabilité financière. En 2023, un tribunal américain a statué contre l’Archive dans une affaire portée par quatre grands éditeurs. Pendant la pandémie de COVID‑19, l’Archive avait temporairement levé sa règle de prêt unique, permettant un accès illimité à des livres numérisés. Le tribunal a jugé cette pratique illégale, et l’appel a été rejeté.
Des fragilités techniques et des menaces de cybersécurité – les archives numériques sont vulnérables aux pannes et aux attaques malveillantes. En octobre 2023, le UK Web Archive de la British Library a subi une cyberattaque majeure qui a mis ses systèmes hors ligne. Près d’un an plus tard, une grande partie de sa collection reste inaccessible. En mai 2024, l’Internet Archive a été victime d’une attaque DDoS massive*, avec des dizaines de milliers de visites automatisées par seconde, paralysant temporairement des services comme la Wayback Machine.
Des contraintes financières et des ressources limitées – l’archivage du Web coûte très cher. L’Internet Archive, malgré son importance mondiale, est financé principalement par des dons. Les archivistes doivent faire des choix difficiles sur ce qu’il faut conserver, souvent au détriment de contenus anciens ou moins visibles. Le volume croissant de données aggrave ce problème : YouTube reçoit plus de 500 heures de vidéo chaque minute, et près d’un milliard d’e‑mails sont envoyés chaque jour.
Une dépendance institutionnelle et un risque d’effondrement – la concentration des efforts sur quelques institutions clés, notamment l’Internet Archive, crée une vulnérabilité structurelle. L’affaire CNET* en 2023 illustre ce phénomène : après avoir supprimé des dizaines de milliers d’articles, l’entreprise a assuré que le contenu était sauvegardé dans la Wayback Machine. Des critiques ont souligné que CNET déléguait sa responsabilité archivistique à un tiers, en tenant l’Internet Archive pour acquis. Cette dépendance, aussi noble soit‑elle, soulève des questions sur la durabilité et la responsabilité.
Conclusion
Alors… quel est le but de tout ça ? Quelle est la solution ultime à ce histoire – peut‑être parce que pour beaucoup, les tweets et les likes d’hier ne sont que cela : d’hier. On ne réfléchit pas plus loin.
Il existe des projets comme AWA* , « The Printed Internet » de Paul Soulellis ou BlookUp* , qui sauvegardent le Web sous forme physique. Mais Internet est trop vaste, trop rapide, et les sociétés modernes sont trop habituées à vivre dans l’instant pour se soucier de leur propre mémoire.
Peut‑être est‑ce normal, voire naturel. C’est une tragédie, mais aussi une routine. Pour nous, c’est comme oublier une conversation sur WhatsApp avec un ami vendredi dernier, ou une vidéo TikTok drôle vue il y a une semaine. Pour les historiens du futur, ce sera comme découvrir un squelette de dinosaure avec d’énormes morceaux manquants.
- ARPANET
premier réseau informatique créé à la fin des années 1960 par le ministère américain de la Défense. Il est considéré comme l’ancêtre d’Internet.
- AWA
(Antarctic World Archive) projet international en Antarctique qui conserve des copies numériques dans des conditions stables, afin de préserver la mémoire de l’humanité pour les générations futures, à l’abri des conflits et catastrophes.
- BlookUp
« Société française qui transforme des contenus numériques (blogs, réseaux sociaux, sites web) en livres imprimés, permettant aux utilisateurs d’archiver leurs publications en format physique.
- CERN
Centre européen de recherche en physique situé en Suisse. C’est là que le tout premier site web a été créé par Tim Berners‑Lee en 1991.
- DDoS massive
(Distributed Denial of Service) C’est une cyberattaque de grande ampleur
qui submerge un site web ou un serveur avec un énorme volume de trafic provenant de nombreux ordinateurs à la fois, le rendant lent ou totalement inaccessible aux utilisateurs réels. - Fandoms
communautés en ligne de fans qui partagent, créent et discutent autour de contenus liés à des livres, films, jeux ou célébrités – formant souvent leur propre culture numérique. communautés en ligne de fans qui partagent, créent et discutent autour de contenus liés à des livres, films, jeux ou célébrités – formant souvent leur propre culture numérique.
- HTML
(HyperText Markup Language) langage de base utilisé pour structurer le contenu des pages web – comme les titres, les paragraphes, les liens et les images.
- HTML5
version moderne du HTML, introduite dans les années 2010, avec de nouvelles fonctionnalités pour la vidéo, l’audio et les contenus interactifs sans besoin de plugins.
- HTTP
(HyperText Transfer Protocol) protocole qui permet aux navigateurs et aux serveurs web de communiquer et d’échanger des données.
C’est ce qui fait fonctionner les sites web. - NCSA
(National Center for Supercomputing Applications) centre de recherche américain qui a développé Mosaic, l’un des premiers navigateurs web populaires, rendant Internet accessible au grand public.
- Newgrounds
lancé en 1995, espace majeur pour animations, jeux et créations d’utilisateurs, influent dans la culture web des débuts.
- SLAC
(Stanford Linear Accelerator Center) laboratoire de physique américain qui a hébergé l’un des premiers sites web en dehors de l’Europe, contribuant à la diffusion du Web dans les années 1990.
- URL
(Uniform Resource Locator) adresse d’une page web ou d’une ressource en ligne – par exemple www.exemple.com.
- WebAssembly
outil puissant qui permet aux sites web d’exécuter des programmes complexes (comme des jeux ou des simulations) à une vitesse proche de celle des logiciels installés.
- WebGL
(Web Graphics Library) technologie qui permet d’afficher des graphismes 3D directement dans le navigateur, souvent utilisée pour les jeux et les visualisations.
- Yahoo
l’un des premiers grands portails web, proposant recherche, actualités, e‑mail et annuaires. Il a marqué l’expérience Internet des années 1990 et 2000.
Glossaire
- Archive Team
(GeoCities), s. d. (consulté le 01/10/2025).
- Tim Berners‑Lee
The Project (premier site web), CERN, 1991 (consulté le 30/09/2025).
- Bibliothèque nationale de France (BnF)
BnF – Archives et manuscrits, 1994 (consulté le 06/10/2025).
- Rupendra Brahambhatt
« Origin of the Internet : Who Invented the World Wide Web ? », Interesting Engineering – Culture, 31 mai 2025 (consulté le 25/11/2025).
- California Learning Resource Network
« Why did Adobe Flash shut down ? », CLRN, 9 juin 2025 (consulté le 08/11/2025).
- Alexandre Chautemp
L’archivage du Web ou le Web comme mémoire des sociétés contemporaines, Cairn.info, 2020 (consulté le 06/12/2025).
- ExecNet
« What Is a Bulletin Board System (BBS)? », s. d. (consulté le 30/09/2025).
- International Internet Preservation Consortium (IIPC)
Site officiel de l’IIPC, 2003 (consulté le 10/10/2025).
- International Web Association (IWA)
International Web Association (page d’accueil), s. d. (consulté le 06/12/2025).
- Internet Archive
La Wayback Machine (page d’accueil), 2001 (consulté le 06/10/2025).
- Internet Archive
Internet Archive (page d’accueil), (consulté le 06/10/2025).
- Jay
« Finding Our Digital Identities : A History of Social Media, The History of the Web, 12 novembre 2018 (consulté le 25/11/2025).
- Margaret Maldonado
« The Rise and Fall of Friendster : A Journey Through the World of Early Social Media », Soft‑hor, 2023 (consulté le 01/10/2025).
- Paul McLellan
« Bulletin Board Systems (BBS): the ‘internet’ before the internet », Paul McLellan Blog, 12 octobre 2015 (consulté le 25/11/2025).
- Emma Remy
Samuel Bestvater
Athena Chapekis« When Online Content Disappears, Pew Research Center – Data Labs, 17 mai 2024 (consulté le 07/10/2025).
- Restorativland
(The Geocities Gallery), s. d. (consulté le 01/10/2025).
- Ruth Rowley
« What Did We Really Lose when Adobe Flash Player Died ? », Overclockers UK – Blog, 24 février 2023 (consulté le 07/10/2025).
- s.n.
« Archivage du web : comment la BnF préserve la mémoire de l’Internet français », Bibliofrance, 10 novembre 2023 (consulté le 06/12/2025).
- Chris Stokel‑Walker
« We’re losing our digital history. Can the Internet Archive save it ? », BBC – Future, 16 septembre 2024 (consulté le 06/12/2025).